چالش جرمشناسی دوم - ذره ذره تا پرچم!
توضیحات
توضیح سوال: هر بایت برای ما مهم است! در هر مرحله نیاز دارید پرونده را به درستی بازیابی کنید وگرنه با مشکل بایت نادرست مواجه میشوید! چون جزییات مهم است، خیلی خیلی مهم است!! پروندهی مربوط به سوال را از اینجا بارگیری کنید.
حل چالش
گام اول
در این چالش یک فایل فشرده به شرکتکننده داده شده است که در مرحلهی اول آن را باز میکنیم. یادآوری میشود که در صورتی که فضای کافی برای فایل غیر فشرده نداشته باشید ممکن است با مشکلات جدی مواجه شوید! بنابراین در ابتدای کار باید به روشی مطمئن شوید که اندازهی فایل اصلی چقدر است. برای این کار از روش زیر استفاده میکنیم:
$ 7z l harBayte.xz
7-Zip [64] 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=en_US.UTF-8,Utf16=on,HugeFiles=on,64 bits,4 CPUs Intel(R) Core(TM) i7-4600U CPU @ 2.10GHz (40651),ASM,AES-NI)
Scanning the drive for archives:
1 file, 4836184 bytes (4723 KiB)
Listing archive: harBayte.xz
--
Path = harBayte.xz
Type = xz
Physical Size = 4836184
Method = LZMA2:23 CRC64
Streams = 1
Blocks = 1
Date Time Attr Size Compressed Name
------------------- ----- ------------ ------------ ------------------------
..... 48302694 4836184 harBayte
------------------- ----- ------------ ------------ ------------------------
48302694 4836184 1 files
همانطور که مشاهده میکنید این پروندهی فشرده فقط شامل یک پرونده است که سایز آن در حدود ۴۸ مگابایت میباشد. پس باز کردن فایل فشرده مشکلی ندارد و به روش زیر انجام میشود:
$ xz -dc < harBayte.xz > harByte
سپس با دستور file نوع آن را بررسی میکنیم:
$ file harByte
harByte: pcap capture file, microsecond ts (little-endian) - version 2.4 (Ethernet, capture length 262144)
در نتیجه یک فایل ضبط شدهی ترافیک داریم.
این فایل را در ابزار WireShark باز میکنیم. همانطور
که در
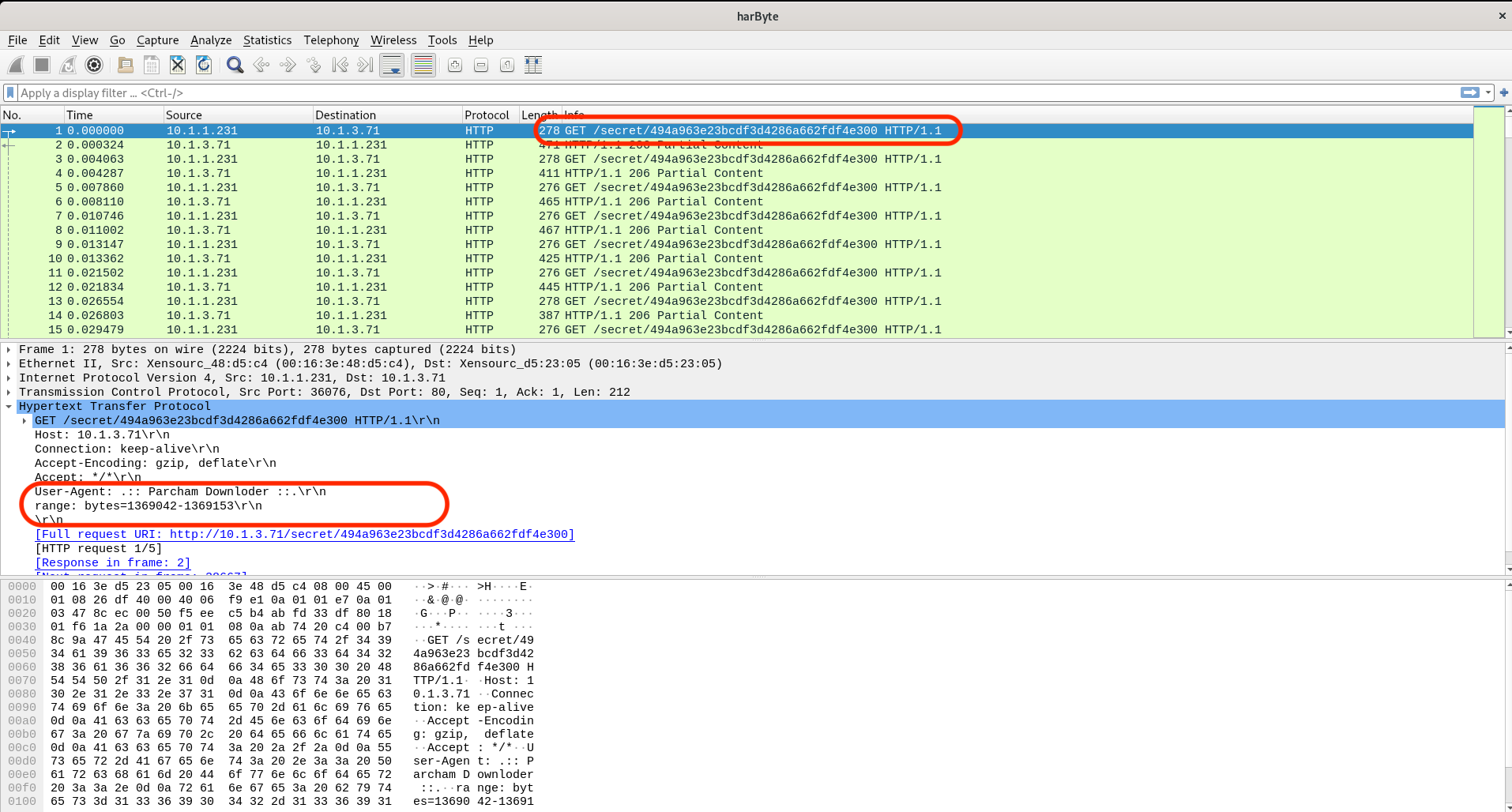
range: bytes وجود
دارد.همانطور که به نظر میرسد فایل به صورت ناقص در پاسخهای متعدد ارسال شده است و بایتهایی که ارسال شده از طریق فیلد مذکور مشخص شده است. ما از دستور زیر برای استخراج داده و بازهی مشخصشده برای بایت استفاده کردهایم. به طور قطع روشهای دیگری هم وجود دارد.
$ tshark -r harByte -Y 'ip.src == 10.1.3.71' -T fields -e http.response.line -e data.data \
| sed 's/^.*Content-Range:.bytes.//' | sed 's/\/1911251\\r\\n//' | sort -n \
| sed '/^\\t\\n$/d' > bytes.txt
این دستورات برای خواندن فیلد byte-range و داده و سپس پردازش و مرتبسازی آنها بر اساس بازهی بایت، نوشته شدهاند. شکل فایل bytes.txt پس از اجرای دستور به صورت زیر خواهد بود:
*
5-13 0a1a0a0000000d4948
5-21 0a1a0a0000000d4948445200003e800000
6-13 1a0a0000000d4948
13-36 48445200003e8000003e8010020000009e8c94ca00000004
34-117 00000467414d410000b18f0bfc6105000000206348524d00007a26000080840000fa00000080e8000075300000ea6000003a98000017709cba513c00000006624b4744adadd8d8e6e6f54104b10004de33494441
71-116 80e8000075300000ea6000003a98000017709cba513c00000006624b4744adadd8d8e6e6f54104b10004de334944
115-118 49444154
116-135 44415478daecd0410dc03000c4b029fca98c4f11
همانطور که مشاهده میشود، ستون اول شامل بازهی بایت و ستون دوم شامل داده است. ستون اول بر اساس شمارهی بایت مرتب شده است و نشان میدهد در ارسال داده همپوشانی وجود دارد و همچنین بایت ۰-۴ ارسال نشده است. بنابراین در اولین مرحله، این بایتها را به یکدیگر میچسبایم، برای این کار از کد پایتون زیر استفاده شده است. اگرچه روشهای سادهتر دیگری هم ممکن است وجود داشته باشد و حتی با استفاده از بش اسکریپت ساده هم این کار انجام بشود، استفاده از این اسکریپت پایتون به این دلیل است که در ابتدای حل سوال فرض شد ممکن است برخی بایتها در دسترس نباشند.
در واقع در ابتدا فایل این بایتها ساخته شد و سپس چون نوع پرونده شناخته شده نبود، لازم بود با استفاده از ابزارهایی مثل strings تلاش کنیم نوع پرونده را متوجه شویم. به همین منظور با مشاهدهی عبارتهای IDAT و HDR و ... به این نتیجه رسیدیم که این پرونده قطعا یک PNG است و ۵ بایت حذف شده دقیقا سرآیند این پرونده هستند که در کد پایتون اضافه شده است.
#!/usr/bin/env python3
file = open("bytes.txt" , "r")
lines = file.readlines()
data_hex = [-1 for i in range(1911251)]
for line in lines:
line = line.strip()
if line == "" or line =="*":
continue
start = int(line.split("-")[0])
end = int(line.split("-")[1].split()[0])
data = line.split("-")[1].split()[1].strip()
ba = bytearray.fromhex(data)
for i in range(start , end+1):
j = start+i
if data_hex[i] ==-1:
data_hex[i] = ba[i - start]
data_hex[0] = 137
data_hex[1] = 80
data_hex[2] = 78
data_hex[3] = 71
data_hex[4] = 13
data_hex_2 = ""
for index , i in enumerate(data_hex):
x = str(hex(i))[2:]
if len(x) == 1:
x = "0" + x
data_hex_2 += x
try:
bytearray.fromhex(x)
except:
print(x)
res = bytearray.fromhex(data_hex_2)
file = open("parcham_1.png" , "wb")
file.write(res)
file.close()
پس از انجام این مرحله به یک پروندهی png رسیدیم که:
$ file parcham_1.png
file.out: PNG image data, 16000 x 16000, 16-bit/color RGB, non-interlaced
$ md5sum parcham_1.png
494a963e23bcdf3d4286a662fdf4e300 parcham_1.png
این پروندهی png یک پروندهی بسیار بزرگ است که شاید در برخی سامانهها اصلا باز نشود که برای این کار باید از تکنیکهای دیگری مثل crop کردن بهره برد. در هر صورت این پرونده به این آدرس اشاره داشت!
https://parcham.io/challenges/forensics/d66a85f8faaf4968fe5aa29a02c3735898522e3d
گام دوم
پس از بارگیری پرونده از پیوندی که در گام اول به دست آوردیم، با یک پروندهی zip مواجه میشویم که با گذرواژه محافظت شده است.
$ file d66a85f8faaf4968fe5aa29a02c3735898522e3d
d66a85f8faaf4968fe5aa29a02c3735898522e3d: Zip archive data, at least v1.0 to extract
$ mv d66a85f8faaf4968fe5aa29a02c3735898522e3d step2.zip
$ unzip -l step2.zip
Archive: step2.zip
Length Date Time Name
--------- ---------- ----- ----
0 2020-09-14 11:28 secret_file/
1911649 2020-09-14 11:40 secret_file/top_secret
1911251 2020-09-14 11:16 secret_file/494a963e23bcdf3d4286a662fdf4e300
--------- -------
3822900 3 files
میتوان برای حل این سوال استفاده از ابزارهای شکستن گذرواژه
مانند john را بررسی کرد که البته به نتیجه نمیرسد.
در نتیجه با جستوجو به دنبال روشهای شکستن
گذرواژهی پروندهی zip به حملات دیگری میرسیم که
یکی از آن ها با نام known plain text attack شناخته میشود.
این حمله برای پروندههای zip بسیار مرسوم است، و در عمل به
این شکل کار میکند که با در اختیار داشتن یکی از
پروندههای موجود، میتوان با استفاده از ابزارهایی به
سایر پروندهها هم دسترسی پیدا کرد.
نکتهی جالب در مورد این گام این است که اسم با نام secret_file مشخص است که شامل ۲ پرونده است که نام یکی از آنها با md5sum پروندهی png مرحلهی قبل یکی است! برای همین فرض کردیم این همان پروندهای است که میتوان برای حمله از آن بهره برد.
یکی از ابزارهای معروف برای این نوع حمله ابزار pkcrack است. که میتوانید آن را بارگیری و نصب کنید. همچنین میتوانید به جای آن از bkcrack استفاده کنید.
برای کار کردن با pkcrack یا
bkcrack لازم است که حتما راهنمای این ابزارها را در
صفحهی گیتهاب خودشان بخوانید.
پس از نصب این ابزار، ابتدا باید پروندهای که مشابه آن را
داریم از پروندهی zip بیرون بکشیم، دقت کنید که ابتدا باید
یک پوشه به نام secret_file بسازیم:
$ mkdir secret_file
$ ./pkcrack/bin/extract step2.zip secret_file/494a963e23bcdf3d4286a662fdf4e300
در گام بعدی باید از پروندهی png که در مرحلهی قبل به دست آوردهایم یک نمونه منطبق با ابزار بسازیم:
$ mkdir parcham_1
$ cp parcham_1.png parcham_1
$ zip parcham_1.zip parcham_1/*
$ rm parcham_1/parcham_1.png
$ ./pkcrack/bin/extract parcham_1.zip parcham_1/parcham_1.png
در نهایت برای شکستن گذرواژه از pkcrack استفاده میکنیم.
میدانیم محتوای پروندهی
secret_file/494a963e23bcdf3d4286a662fdf4e300 برابر
با مقدار رمزگذاریشدهی پروندهی
parcham_1/parcham_1.png است. به
pkcrack این رابطه را میفهمانیم و از آن
میخواهیم که قفل پروندهی step2.zip را با
کمک همین دانش، بشکند و آن را رمزگشایی کند و حاصل را در
پروندهی جدید decrypted_file.zip بریزد که یک
پروندهی zip بدون گذرواژه است:
$ ./pkcrack/bin/pkcrack -C step2.zip -c secret_file/494a963e23bcdf3d4286a662fdf4e300 -p parcham_1/parcham_1.png -d decrypted_file.zip
Files read. Starting stage 1 on Wed Sep 23 22:00:34 2020
Generating 1st generation of possible key2_90813 values...done.
Found 4194304 possible key2-values.
Now we're trying to reduce these...
Lowest number: 981 values at offset 86110
Lowest number: 961 values at offset 86108
.
.
.
Lowest number: 110 values at offset 54219
Lowest number: 97 values at offset 25243
Done. Left with 97 possible Values. bestOffset is 25243.
Stage 1 completed. Starting stage 2 on ...
Ta-daaaaa! key0=1d2ab3ea, key1=8503eed0, key2=df1eab08
Probabilistic test succeeded for 65575 bytes.
Ta-daaaaa! key0=1d2ab3ea, key1=8503eed0, key2=df1eab08
Probabilistic test succeeded for 65575 bytes.
Stage 2 completed. Starting zipdecrypt on ...
Decrypting secret_file/top_secret (6297edcd5b5a4e047b5f115d)... OK!
Decrypting secret_file/494a963e23bcdf3d4286a662fdf4e300 (c010ae771bfd2dd070070c5a)... OK!
سپس پرونده را از حالت فشرده خارج می کنیم و می بینیم که پروندهی top_secret هم یک پروندهی png دیگر است.
$ unzip decrypted_file.zip
Archive: decrypted_file.zip
creating: secret_file/
inflating: secret_file/top_secret
inflating: secret_file/494a963e23bcdf3d4286a662fdf4e300
این پرونده به آدرس زیر اشاره میکند:
{kind=link}
https://parcham.io/challenges/forensics/04926e840fbb43d8f097aa337a49c20fcbc99703
گام سوم
در این مرحله باز هم یک پرونده داریم که نوع آن را نمیدانیم:
$ file 04926e840fbb43d8f097aa337a49c20fcbc99703
04926e840fbb43d8f097aa337a49c20fcbc99703: data
$ binwalk 04926e840fbb43d8f097aa337a49c20fcbc99703
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
120 0x78 bzip2 compressed data, block size = 900k
75542 0x12716 bzip2 compressed data, block size = 900k
133511 0x20987 bzip2 compressed data, block size = 900k
با استفاده از برنامهی binwalk به نظر میرسد که فقط سه
پروندهی فشرده با قالب bzip2 داریم.
از خود binwalk برای استخراج پروندهها استفاده میکنیم:
$ binwalk -e 04926e840fbb43d8f097aa337a49c20fcbc99703
$ ls _04926e840fbb43d8f097aa337a49c20fcbc99703.extracted/
12716 20987 78
دستور فایل به ما میگوید که پروندهی شمارهی 78
یک پروندهی png است و دو پروندهی دیگر از نوع data
هستند.
بنابراین احتمال این که سه پرونده مربوط به یک png باشند وجود
دارد. در نتیجه به روش زیر این سه را بهم میچسبانیم:
$ cd _04926e840fbb43d8f097aa337a49c20fcbc99703.extracted/
$ cat 78 12716 20987 > ../parcham_3.png
$ cd ..
باز هم به یک پروندهی png میرسیم که مسیر زیر را نشان میدهد:
https://parcham.io/challenges/forensics/2f0876d6ec354e314a0cd1f2c7c92bc1341a4006
راه حل خیلی درست!
اگر سرآیند این پرونده را بخوانید متوجه میشوید که با یک قالب jigdo مواجه هستید. این قالب برای توسعهدهندگان دبیان ایجاد شده است که امکان بارگیری به سبک خلاقانهای را فراهم میکند. بنابراین روش درست حل این قسمت با دستور زیر است:
$ jigdo-file mi -t 04926e840fbb43d8f097aa337a49c20fcbc99703 --image parcham_3.png
گام چهارم
در این مرحله نیز به یک پرونده با نوع data مواجه هستیم:
$ file 2f0876d6ec354e314a0cd1f2c7c92bc1341a4006
2f0876d6ec354e314a0cd1f2c7c92bc1341a4006: data
اما این بار برنامهی binwalk هیچ خروجی ندارد.
بنابراین با استفاده از ghex پرونده را باز میکنیم:
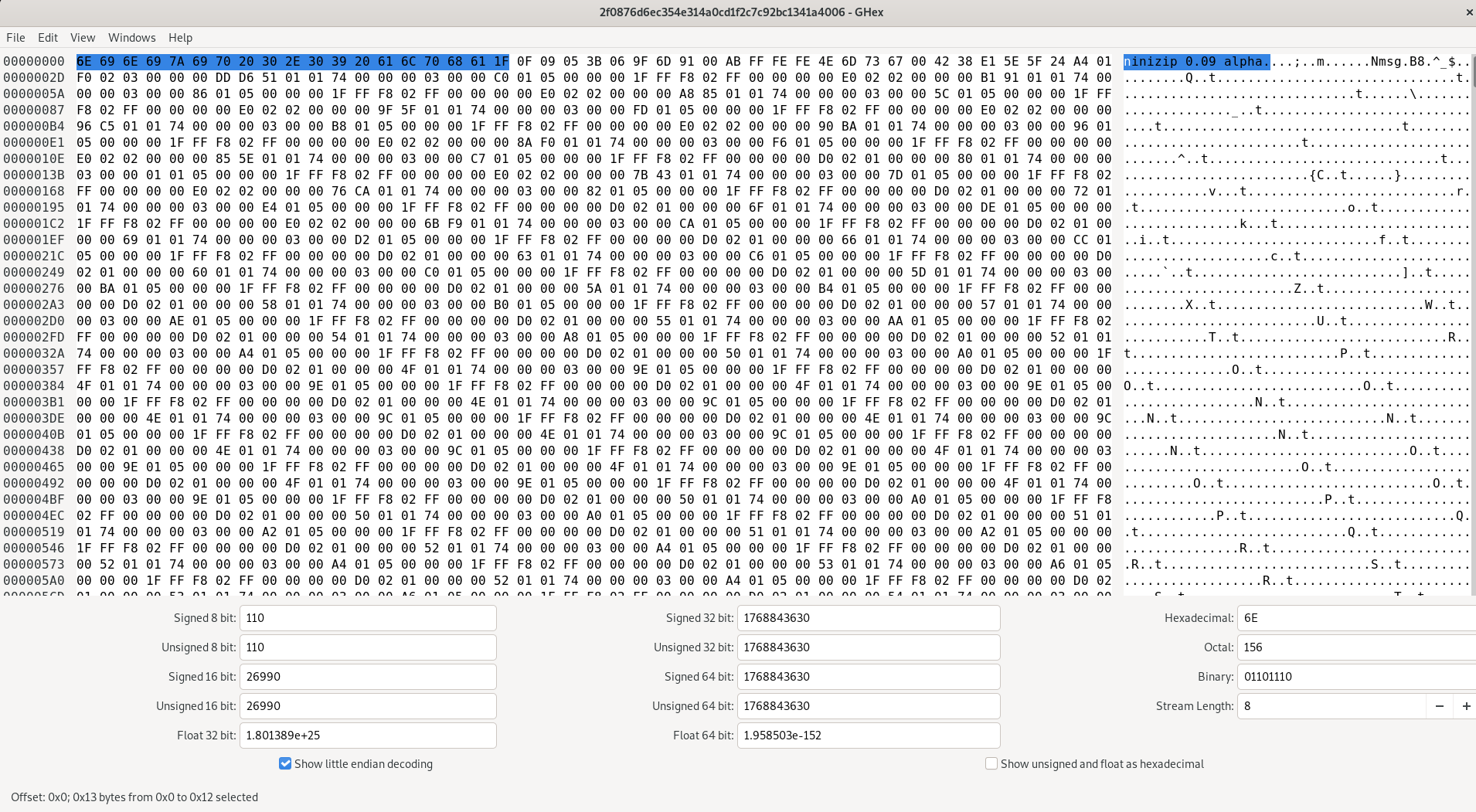
با کمی جستوجوی سرآیند به این نتیجه میرسیم که
ممکن است این پرونده یک پروندهی NanoZip باشد.
پس نیاز داریم یک پروندهی NanoZip بسازیم و بررسی کنیم
سرآیند را به چه شکلی باید تغییر دهیم و سپس چگونه پرونده را از
حالت فشرده خارج کنیم.
پس از نصب nanozip (توصیه
میکنیم نسخهی ۳۲ بیتی لینوکس را نصب کنید چون
نسخهی ۶۴ بیتی ایراد دارد)، یک پروندهی نمونه
میسازیم که سرآیند به شکل زیر است:

در نتیجه بعضی بایتها تغییر کردهاند و ۲ بایت حذف شده. آنها را اصلاح میکنیم و پروندهی جدید را step_4.nz مینامیم.
در ابتدا فهرستی از پروندهها را میگیریم تا مطمئن شویم مشکلی با باز کردن این پرونده پیش نمیآید:
$ ./nz l step_4.nz
NanoZip 0.09 alpha/Linux32 (C) 2008-2011 Sami Runsas www.nanozip.net
Intel(R) Core(TM) i7-4600U CPU @ 2.10GHz|2754 MHz|#2+HT|4191/7655 MB
Archive: a.nz
checksum perm yyyy-mmm-dd hh:mm:ss size file
32a41e97 0644 2020-Sep-14 11:19:20 20 GB msg
cc0f082b 0644 2020-Sep-14 11:11:34 1869 KB 8e76a7fd8a22e35fc12feaf7e2504b1f
Total of 2 files, 21 476 750 243 bytes.
همانطور که مشخص است این پروندهی فشرده شامل یک
پروندهی ۲۰ گیگابایت و یک پروندهی دیگر است که به نظر
پروندهی دوم مهمتر است (قالبی شبیه به مراحل قبلی
دارد). بنابراین چون به اندازهی کافی فضا نداریم باید به
روشی فقط پروندهی دوم را باز کنیم. با کمی
جستوجو در پروندهی step_4.nz در مییابیم
که پروندهی دوم خودش یک NanoZip است و از بایت
0x29d7شروع شده است.
پس ابتدا به روش زیر پرونده را استخراج میکنیم و سپس آن را
از حالت فشرده خارج میکنیم:
$ dd if=step_4.nz of=chopped.nz bs=1 skip=10711
$ ./nz x chopped.nz
در نهایت باز هم به یک پروندهی png میرسیم که شامل
آدرس زیر است:
https://parcham.io/challenges/forensics/604e54fa87065a7c5a52f96eae1bf63ad5df09eb
گام آخر!!
در این مرحله با باز کردن پیوند مرحلهی قبلی به یک پرونده
png میرسیم که میگوید پرچم را از قبل داریم!!
این یعنی پرچم در یکی از مراحل قبلی یا ترکیبی از مراحل قبلی مخفی
شده است.
از انجایی که شرکتکننده در هر مرحله یک یا چند پرونده
ساخته است پس باید بار دیگر آنها را بررسی کند تا به نتایجی
برسد.
البته این گام کمی زمانبر است. ولی واضح است که در هر مرحله
یک پروندهی png داریم. اگر بار دیگر نگاهی به آنها
داشته باشیم
برای اینکار از ابزار pngsplit بهره
میگیریم و توجه داریم که این ابزار همهی چانکهای
png را خروجی میدهد.
$ mkdir all_pngs
$ cp parcham_1.png parcham_2.png parcham_3.png parcham_4.png parcham_5.png all_pngs && cd all_pngs
$ pngsplit parcham_1.png parcham_2.png parcham_3.png parcham_4.png parcham_5.png
توصیه میشود برای مطالعهی بیشتر به
ساختار پروندهی png
مراجعه شود.
برای راحتی کار، به پوشهی مراجعه
کنید که شامل هر ۵ پروندهی png مراحل و چانکهای
آنها است.
در نهایت ما نیاز به چانکهای ابتدایی و چانک انتهایی داریم که خوشبختانه چون اندازه پروندهی عکسها یکی است میتوان از ابتدا و انتهای همان پروندهها استفاده کرد. پس با دستور زیر یک پروندهی جدید میسازیم:
$ cat parcham_1.png.0000.sig parcham_1.png.0001.IHDR \
parcham_1.png.0002.gAMA parcham_1.png.0003.cHRM \
parcham_1.png.0004.bKGD parcham_1.png.0010.IDAT \
parcham_2.png.0010.IDAT parcham_3.png.0010.IDAT \
parcham_4.png.0010.IDAT parcham_5.png.0010.IDAT \
parcham_5.png.0011.IEND > Final.png
و در نهایت پس از تلاش بسیار به پرچم میرسیم!!
parcham{Th13_0n3_wa5_harder_be_patient_&_learn!!}